PROTECT YOUR DATA
Take complete control of your sensitive data with minimal effort
comforte Data Security Platform

DISCOVER & CLASSIFY

INVENTORY
AUTOMATION
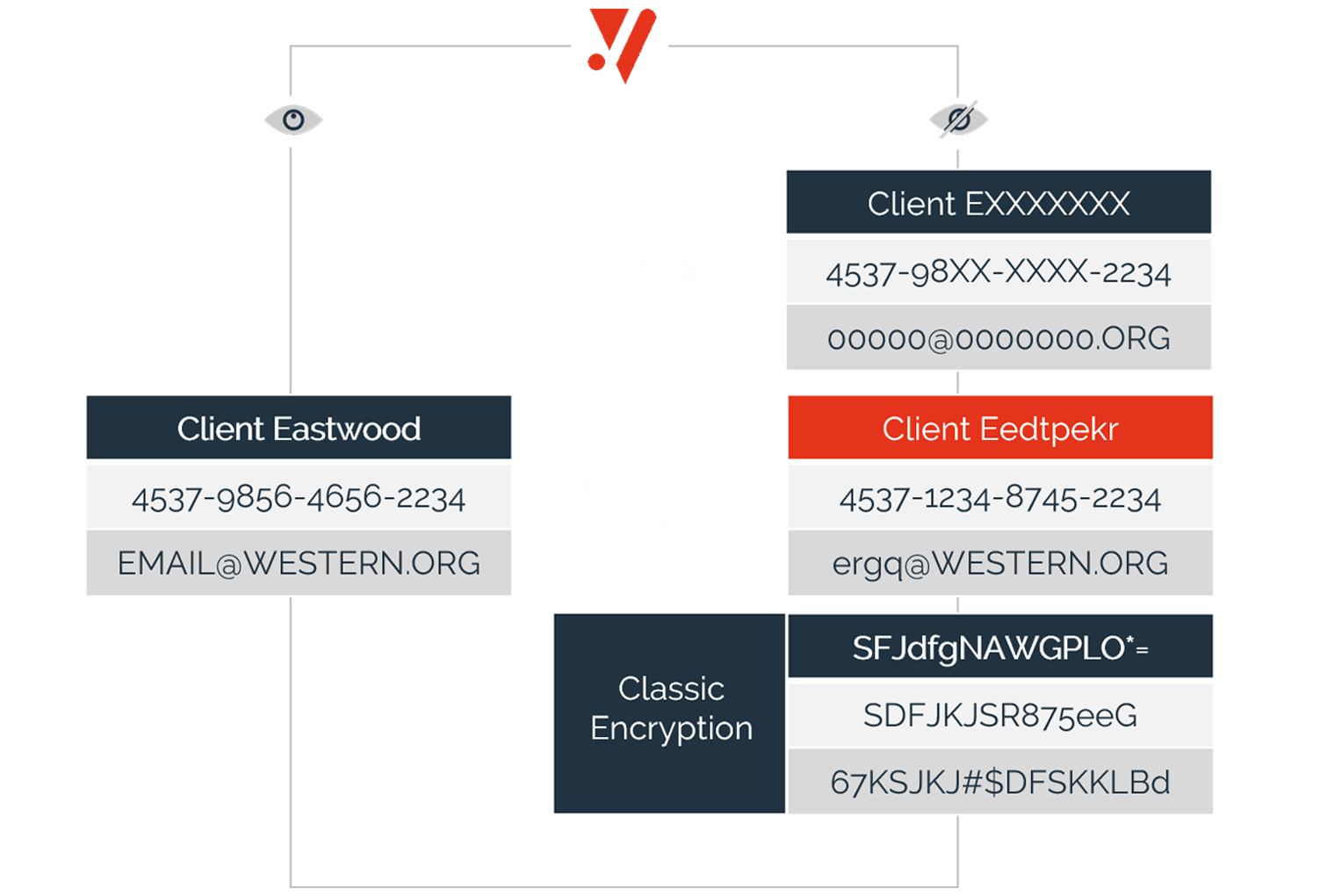
A high level of flexibility in defining security policies allows you to strike the right balance between securing data and preserving data utility.
Integration with Identity Access Management (IAM) and Security Information and Event Management (SIEM) systems provides seamless policy enforcement and control.

Provide end-to-end protection for structured and semi-structured data across the Enterprise: On-premises, Cloud, SaaS, Hybrid, and for cloud-native.
Data is always protected; regardless if it is at-rest, in-motion, or in-use in applications & analytics.
Secret isolation and a central access model, enable full control over protected data while eliminating complex key management.

Easily connect any data flow, business application, or data store with our platform using smart interceptors, or powerful APIs supporting any language or script.
Infrastructure-as-Code model allows automated provisioning and delivery, and the platform is deeply integrated with orchestration systems like Kubernetes.
Deploy data security anywhere: From on-premises to hybrid to multi-cloud to cloud-native.

Why customers choose our platform
- Protect data elements from capture. Keep them protected, at-rest, in-motion, in-use - in applications and analytics.
- Preserve data utility while keeping it secure and eliminate complex key management challenges.
- Deep integration into Kubernetes and VMware combined with Data-Security-As-Code for DevOps & automation and modern IT delivery.
- Transparent Integration with data flows and applications let you deploy ~10x faster compared to traditional API-driven approaches.







Discover’s Pulse network chooses comforte AG for PCI compliance
- Robust security with zero latency
- Best-in-market solution for protecting PANs in accordance with PCI compliance
- Seamless integration and intuitive configuration allowed for rapid deployment and adoption

